
It Started With Sherlock Holmes
I was back at my parents' home in Sri Lanka — thousands of kilometres from where I live now — rereading Sherlock Holmes. The same books I'd loved as a kid, pulled off the same shelf.
There's something about being in your childhood home that makes your mind wander in useful directions. You're not in work mode. You're not optimising anything. You're just... reading. And somewhere between "The Red-Headed League" and "A Scandal in Bohemia," a thought started forming.
It wasn't about Sherlock Holmes specifically. It was about the experience of reading something so well-crafted that you lose yourself in it — the voice, the structure, the way Conan Doyle makes you feel like you're sitting in that room at 221B Baker Street while Holmes explains the whole thing.

And I thought: What if I could read something like this about any topic I'm curious about? Not a blog post. Not a listicle. Not a ChatGPT dump. A real article — with actual research, a deliberate angle, a consistent voice, written in whatever style fits the subject.
What if I wanted to read about AI and deepfakes, but told in the voice of Sherlock Holmes deducing the case? What if I wanted a World Cup history piece that reads like a literary essay? What if I wanted a technical analysis of AI agents that's sharp enough for an executive audience?
Those articles don't exist. Nobody writes them because nobody commissions them. They live in the gap between "I wish I could read this" and "nobody's going to spend 8 hours making it."
I kept turning the idea over for days, between family dinners and afternoon naps and more Holmes stories. What would it take to build a machine that writes the article I wish existed? Not me writing it. Not me fixing an AI draft. A system — like a small editorial team made of AI agents — that does the research, picks an angle, writes it properly, reviews it seriously, and hands me something I'd genuinely want to read.
And then I did what I always do when an idea won't leave me alone — I sat at my old desk, opened Claude, and started talking it through. Not coding. Just brainstorming. Working through the architecture between family meals and lazy afternoons. The conversations stretched across several days, and by the end I didn't have a vague idea anymore — I had a 2,000-line plan.
The building happened there too. The whole thing — brainstorming, planning, coding, debugging — all done during the vacation, mostly from the same desk where I'd first learned to write code, occasionally from the sofa when the desk felt too much like work. And one of the first things I asked the finished system to do was write about AI and deepfakes — in the voice of Sherlock Holmes. Here's what came back:
"It was, I confess, not the sort of case to which Scotland Yard commonly summons me. No body lay upon the carpet, no jewel had vanished from a locked casket, no bloodstain required the lens. Instead, there stood before us a question of selection — of appetite, even. Humanity, having been handed one of the most formidable cognitive instruments in its history, appears chiefly interested in asking it to fabricate phantoms."
"You are severe, Holmes," said Watson, with that generous buoyancy which has preserved him from cynicism. "Surely the same intelligence is being turned toward medicine, climate, and scientific research as well?"
I glanced at him. "You are quite right to ask, Watson," I replied. "For that is what makes the matter so curious."
I read it sitting at the same desk where the idea had started — and for a moment I was in that room at 221B Baker Street, the same way I'd felt reading the paperback a few weeks earlier. Except this time, Holmes was talking about deepfakes.
The First Conversation: "I Want to Build This Thing"
I sat at my old desk — the same one where I'd learned to code years ago — opened Claude on my phone, and laid out what was in my head. Not code. Not specs. Just the feeling:
"Is it possible to build an agentic workflow to create articles? I want end to end — like when I give a topic it will do research, then add those research to draft files, then maybe writers write content, then a supervisor verifies the result and also asks to rewrite it. Can we do it?"
The response was immediate and enthusiastic — yes, this is a great use case, here's a basic version. And within minutes, Claude had sketched out a simple three-agent pipeline: Researcher, Writer, Supervisor, all running through Claude's API.
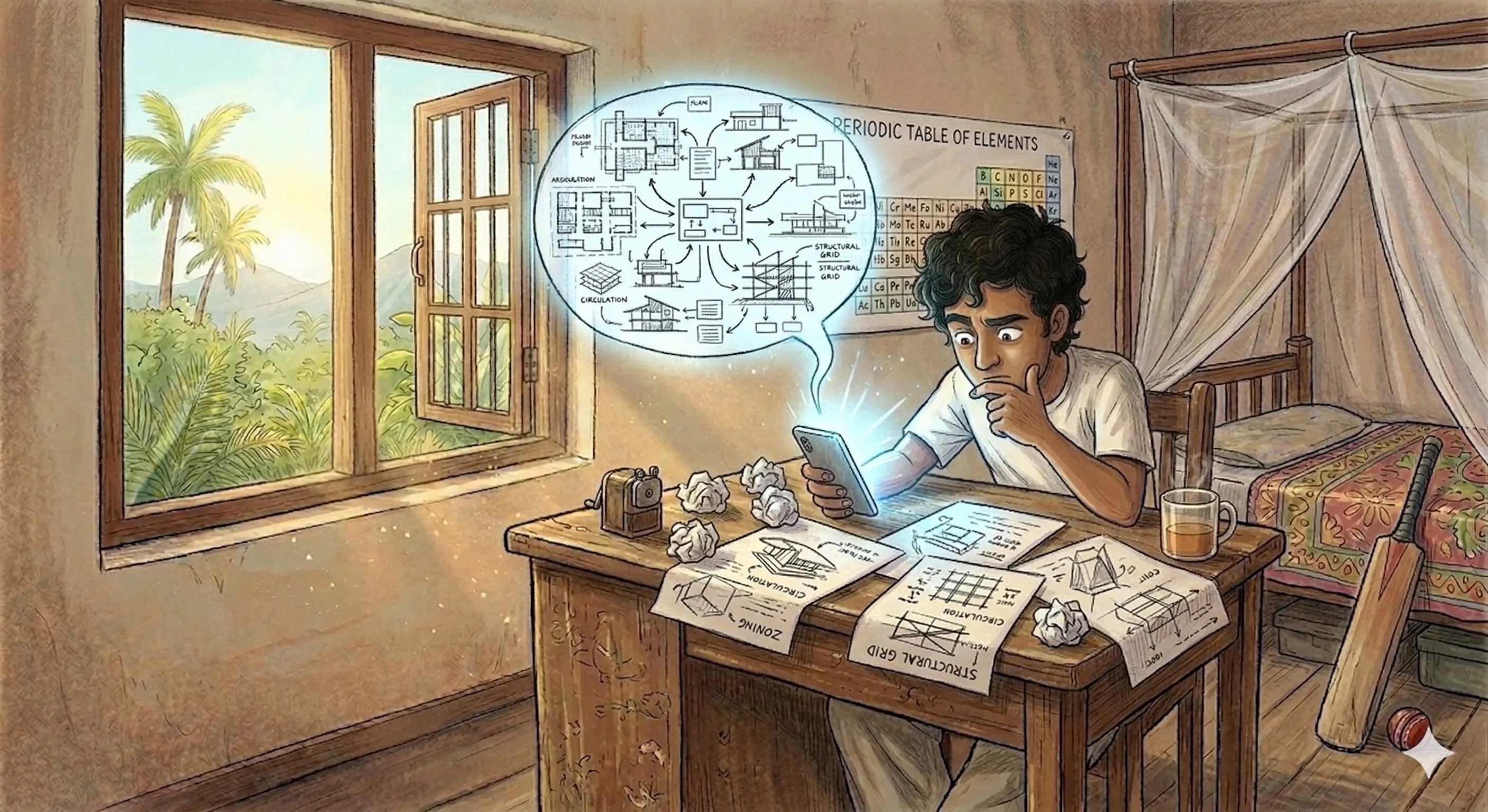
It was a working concept. It was also, I realised immediately, too simple.
Not wrong — the bones were right. But I'd spent days thinking about how good articles actually get made, and I knew from experience that the gap between "AI writes a draft" and "this is something I'd want to read" is enormous. The gap isn't in the writing. It's in everything that happens before the writing.
So instead of saying "build it," I said: "As you think, this is a basic version, right?"
That decision — to brainstorm before building — changed everything.
The Brainstorm That Became an Architecture
What followed was hours of back-and-forth that felt less like prompting an AI and more like whiteboarding with a colleague who happens to think very fast and never needs coffee.
"What if we had a Planner?"
The first big idea came from a simple observation: good articles don't just have research and writing. They have an angle. The same set of facts about AI in healthcare can become a patient-focused story, a technical deep-dive, or a policy analysis. The choice of angle determines everything downstream — structure, voice, audience, what to emphasise, what to leave out.
So I asked: "Maybe we need a Planner agent? One that reads the research and proposes different angles before anyone starts writing?"
Claude ran with it. What if the Planner proposes three distinct angles? Each with a target audience, a suggested tone, headline options? And then — this was the key — I pick the one I want before the writers start.
That became Human Gate 2. And it changed the entire system from "autonomous article generator" to "article generator with editorial judgment at the most important moment."
"What if each section had a different writer?"
This one came from thinking about how the revision loop should work. If the supervisor says section 3 is weak, I don't want to regenerate the entire article. I want to rewrite just that section.
Which means sections need to be independent files. One file per section. The supervisor reads the whole assembled article but gives feedback per-section. And on revision, the writer sees all the other sections for context but only rewrites their assigned piece.
We went deep on the file structure:
Claude designed a SectionManager class with methods like get_writer_context() — which returns the writer's own section as editable, plus all other sections as read-only context. Clean separation of "your job" versus "the world around you."
This felt like the kind of design decision that would save hours of debugging later. And it did.
"Should we use multiple LLMs for research?"
This is where it got interesting. Claude's initial suggestion was straightforward: one researcher agent with web search. Simple, effective.
But I kept pushing: "What if we use different LLMs? Claude, Gemini, GPT — each analysing the same sources but from different perspectives?"
The argument for it: different models have different training data, different biases, different analytical strengths. Three researchers finding the same fact independently means higher confidence. Three researchers finding different things means broader coverage.
The argument against it: more complexity, more cost, more API calls. And then you need a merger agent to reconcile three different research outputs.

We decided the diversity was worth it. But that created a new question — should each researcher do their own web search? That's three separate search calls, potentially finding different pages, with no way to compare apples to apples.
That question led directly to the most important architectural decision in the entire project.
The Tavily Decision: Decoupling Search From Thinking
Claude initially suggested using each LLM's native search — Claude's web search tool, Gemini's grounding, OpenAI's search API. It's simpler. Fewer moving parts. One API call does both the searching and the synthesis.
I pushed back hard.
"If the LLM searches and synthesises, I can't see what it found. I can't verify the sources. I can't cache the results. And I definitely can't give the same sources to three different models for cross-verification."
This led to a research session right there in the conversation. I asked Claude to look into how each provider handles web search, and it laid out the differences:
- Claude's search results are encrypted — you literally can't read them, only the model can
- OpenAI has two different search systems — one where the model decides when to search, one that always searches
- Gemini uses "grounding" with its own metadata format
Three providers, three completely different approaches, three different data formats. Trying to normalise all of that would be a nightmare. And even if I did, I still couldn't inspect the raw source material or cache it.
So I asked: "What if we use something like Firecrawl or Tavily as a dedicated search layer? Search once, get clean content, then feed that content to all three LLMs?"
We went back and forth on Firecrawl versus Tavily. Firecrawl is more powerful — it can crawl entire sites, handle JavaScript rendering, do structured extraction. Tavily is simpler — search plus scrape in one call, returns clean markdown, purpose-built for LLM consumption.
For our use case (topical research, not site crawling), Tavily was the right fit. Simpler API, lower cost, and the output is already optimised for LLMs to read.
The architecture became:
This was the moment the system went from "interesting prototype" to "something architecturally sound." Every downstream decision flowed from this one: caching, cost control, debuggability, the ability to re-run synthesis without re-searching.
The Job Registry: "What if it crashes halfway through?"
This came from a practical fear. Each article run involves 15-20 API calls across multiple providers. Rate limits, timeouts, safety filters, network errors — any of these can kill a run mid-pipeline. And at $0.60 per run, I didn't want to redo the expensive research phase because the tone harmoniser timed out at the end.
I asked: "Can we keep track of each request? Like, when we enter a topic, we create a record with a request ID. If we want to pause and continue later, or retry a specific stage, we can."
Claude designed a job registry backed by SQLite — every run gets a short ID, every stage is tracked independently with its status and token usage. Hit Ctrl+C during a run and it saves a checkpoint. Type resume a1b2 and it picks up from the last completed stage. The orchestrator saves state after every phase, so you never lose more than one stage of work.
None of this is glamorous work. But it's the kind of infrastructure that makes the difference between a demo and a tool you actually use.
The Supervisor Voting System
I knew from the start that I wanted multiple reviewers. One LLM reviewing its own work is like asking the author to be their own editor — they have blind spots to their own patterns.
But how should multiple supervisors work together? Claude proposed three strategies:
- Average: take the mean score across all supervisors. If it's above the threshold (8.0), approve.
- Unanimous: every supervisor must approve. Strictest.
- Majority: more than 50% must approve. Middle ground.
We designed a SupervisorVoting class with a configurable strategy. Each supervisor returns structured JSON with per-section scores across four dimensions: plan adherence, quality, accuracy, and flow.
The beautiful part: supervisors don't see each other's reviews. They review independently, like blind peer review in academia. The voting system only aggregates after all reviews are in.

We also designed the revision loop: if sections fail, the writer gets the combined feedback from all supervisors but only rewrites the flagged sections. Other sections are untouched. The writer also sees all sections as read-only context (via the SectionManager) so the rewrite maintains flow and avoids redundancy.
The 2,000-Line Plan
By the end of the brainstorming — which happened across multiple sessions, with me pushing ideas and Claude helping me think through implications — we had a comprehensive project plan that covered:
- Complete file/folder structure for the Python project
- Every agent's specification: inputs, outputs, behaviour, system prompts
- The full Tavily integration with caching and multi-query support
- The provider comparison matrix (how Claude, OpenAI, and Gemini each handle web search differently)
- The job registry with SQLite schema, stage tracking, and resume logic
- The supervisor voting system with three strategies
- The orchestrator state machine with parallel execution
- A startup validation system that tests API keys and model availability before spending tokens
- The CLI interface with commands for run, resume, retry, pause, jobs, status, cost
- An implementation roadmap broken into 5 phases
- Test cases for every major component
It was roughly 2,000 lines of markdown. Not code — plan. A blueprint detailed enough that Claude Code could work from it directly, with clear specifications for every module, every interface, every data flow.
That plan was the foundation. When I finally opened Claude Code and started building, I wasn't starting from "I have an idea." I was starting from "I have a detailed architecture, I know what every file does, and I know how every agent communicates."
The building went fast because the thinking was already done.
What I Learned About Brainstorming With AI
Push Back Constantly
The LLM's first suggestion is rarely the best one. It's the safest one — the most straightforward, least controversial approach. When Claude suggested native LLM search, it was the simpler option. When it suggested a fully autonomous pipeline, that was the path of least resistance.
Every time I pushed back with "but what about..." or "I don't think that works because...", the design got better. The LLM isn't precious about its ideas. It will happily help you build the alternative. But it won't push back on your behalf unless you give it a reason to.
Talk About Problems, Not Solutions
The best design decisions came from describing failures, not prescribing fixes.
I didn't say "add a Planner agent." I said "the article doesn't have a clear angle." Claude then helped me figure out that the missing piece was a planning stage, and we designed it together.
I didn't say "add a job registry with SQLite." I said "what if it crashes halfway through?" Claude then proposed the tracking system, and we iterated on the schema.
When you describe the problem, you give the LLM room to suggest approaches you haven't considered. When you prescribe the solution, you constrain it to validating your idea.
The Plan Is the Product
The 2,000-line plan wasn't overhead. It wasn't documentation. It was the product — in the same way that an architect's drawings are the product before the building exists.
When I handed that plan to Claude Code for implementation, the building phase was dramatically faster and produced dramatically better results than if I'd started coding from a vague idea. Every module had a clear spec. Every agent had defined inputs and outputs. Every edge case had been discussed.
If you're building something complex with an LLM coding partner, spend the time on the plan. It's the highest-leverage work you'll do.
From Plan to Reality: What Changed
The plan wasn't sacred. Implementation taught me things the brainstorm couldn't anticipate.
The query planner, for example, was supposed to be a function inside the orchestrator. During implementation, I pulled it out into its own agent with a human gate — once I saw the generated queries, I realised I always wanted to tweak them before spending API credits on search. That instinct to add human control at the right moment came from using the system, not from planning it.
The supervisor panel grew from two reviewers to three, because two creates a tiebreaker problem you don't notice until you're staring at a 50/50 split. Competitive writing mode — where multiple LLMs write the same section and a judge picks the winner — wasn't in the plan at all. It emerged when I caught myself doing this manually and thought: why isn't this in the pipeline?
And then there were the surprises nobody plans for: Gemini blocking a healthcare article with safety filters, which led to a fallback writer mechanism. Two additional providers (Qwen and DeepSeek) added because free-tier models turned out to be perfect for research synthesis where you want diversity, not peak quality.
Every change was an improvement. But they were improvements on top of a solid foundation. The plan gave me the structure; implementation gave me the refinements.
The Real Takeaway
Don't start by coding. Start by talking.
Describe what you want to build. Describe the problems you're trying to solve. Push back on the first suggestions. Explore alternatives. Design the file structure, the data flow, the failure modes. Write it all down as a plan.
Then, when you finally open your code editor, you're not exploring — you're executing. And that's where LLMs as coding partners truly shine: translating a clear vision into working code, fast.
You've already seen what the machine produced — Holmes deducing the case of humanity's appetite for deepfakes. But it also wrote a literary essay about World Cup heartbreak, a sharp business strategy piece about AI agents, and a witty cultural commentary about AI memes. Four articles, four completely different voices, same pipeline, same $0.62 each.
Holmes would have appreciated the method. The detective always insisted on the same approach: observe first, deduce second, act third. The machine I built does exactly that — it researches, it plans, it writes, it reviews. It just does it with eight agents instead of one consulting detective.
The system started not with code, but with a conversation. And the conversation started at the same desk where I'd done my homework as a kid — the one that watched me learn to code, struggle through exams, and dream about building things. That desk knows more about me than any colleague ever will.
The articles this pipeline produces are published at blueandyeliwrite.com.