
Part 1 ended with a 2,000-line architecture plan and the kind of confidence you only get from things that exist solely as documents. Then I opened a terminal, typed run "AI in healthcare", and the pipeline broke in three different ways I hadn't planned for.
Where the Plan Ended and the Build Began
The briefest possible recap. The pipeline I designed has nine stages: query planning, search, multi-model research, merging, angle proposal, plan building, parallel section writing, multi-supervisor review, and tone harmonisation. Five providers. Two human gates. One config file that routes every "agent role" to whichever model I feel like using that week — Claude Sonnet, Gemini 2.5 Pro, GPT, Qwen, DeepSeek. None of those are baked into the architecture; point the config somewhere else and the same pipeline runs with different models.
Built solo over a long vacation, with Claude Code as the implementation partner. The 2,000-line plan covered most of it.
Most of it.
What follows is the story of three things the plan didn't anticipate, and one feature I didn't plan at all that turned out to matter most.
Bug 1: The Researchers DDoS'd My Own Pipeline

The first run got further than I expected. Query planning worked. The Tavily search returned 23 sources. Three researchers fired off in parallel — and then everything just stopped.
Not crashed. Stopped. The next API call — a tiny request asking the planner to propose three editorial angles — kept failing with a 429. Then the next one. Then the next one. For minutes.
I went looking. The three researchers were all configured to use Claude — different system prompts, different analytical "personalities," but the same underlying model. They'd hit the 30K-tokens-per-minute rate limit simultaneously, and the rate window wouldn't clear until it cleared. The planner wasn't competing with anything; it was just standing in line behind the wreckage of the previous burst.
Two fixes, one obvious, one less so.
The obvious one: actually read the retry-after header instead of guessing. I'd been using exponential backoff because that's what every tutorial does. Anthropic's API tells you exactly how long to wait — I just hadn't been listening.
1@staticmethod 2def _retry_wait(exc, attempt): 3 header = exc.response.headers.get("retry-after") 4 if header: 5 return min(float(header), 120.0) 6 return min(60.0 * attempt, 120.0) # fallback
The less obvious one: detect when "parallel" agents share a provider and quietly run them sequentially instead. There's no point firing three Claude calls at the same instant if you know they're going to collide. The orchestrator now compares the resolved model for each role, and if any two researchers map to the same model, they queue up:
1models_used = {self._router.get_model(role) for role, _ in researcher_configs} 2run_sequential = len(models_used) < len(researcher_configs)
What I didn't expect was how much this changed my mental model of the system. I'd been thinking of the pipeline as "an AI tool." It isn't. It's a distributed system that happens to be made of LLMs, and most of the bugs you're going to hit are the same ones you'd hit running any other multi-provider workload — rate limits, retries, head-of-line blocking, transient timeouts. The intelligence is the easy part. The orchestration is the work.
Bug 2: Gemini Refused to Write About Healthcare

The second bug was funnier and slightly disturbing.
The pipeline was running clean. Research had merged. The planner had proposed angles, I'd picked one, and sections were being written in parallel by Gemini 2.5 Pro. The terminal was a satisfying wall of green ticks.
Except for one section. Under the Hood: From Voice in the Exam Room. It came back as None.
Not an error. Not an empty string. None. I dug into the SDK and discovered that Gemini's response.text property raises an exception when the safety filter trips, instead of returning whatever was generated. The exception was being swallowed somewhere deeper in my own code, and the section had just silently disappeared.
The trigger? The article was about AI in healthcare. Gemini's safety filter took one look at the words patient, diagnosis, and exam room in the same paragraph and decided the safest response was nothing at all.
I want to dwell on this for a second, because it's the kind of bug you can't really plan for in an architecture document. My system was generating prose, reviewing prose, harmonising prose. The content was being analysed by another LLM half a second later. There was no user, no prompt injection, no harmful content — just a model writing about a topic that 60,000 other articles cover every week. And it refused.
Two fixes again.
Bypass response.text and pull text out of the candidate parts directly:
1if response.candidates: 2 candidate = response.candidates[0] 3 parts = [p.text for p in candidate.content.parts if hasattr(p, "text") and p.text] 4 text = "".join(parts) or None
And turn the safety filter off, because for this use case it's not adding anything:
1_SAFETY_SETTINGS = [ 2 types.SafetySetting(category="HARM_CATEGORY_HARASSMENT", threshold="OFF"), 3 types.SafetySetting(category="HARM_CATEGORY_DANGEROUS_CONTENT", threshold="OFF"), 4 # ... 5]
But the deeper fix — the architectural one — was a section_writer_fallback role. If a section comes back empty for any reason (safety filter, network error, bad JSON, model having a bad day), the orchestrator automatically retries it with a different provider:
⚠ Under the Hood: From Voice in the Exam Room — failed — will retry with fallback Retrying 1 section(s) with fallback writer (claude-sonnet-4-6)... ✓ Under the Hood: done (fallback)
One line of YAML, one whole class of failure mode handled. I'd planned for the system to be multi-provider for quality reasons — different models, different perspectives, richer synthesis. Turns out the bigger reason is that providers have moods, and a pipeline with only one provider per role is one safety filter away from a hole in the article.
Bug 3: Three Supervisors Looked at the Same Section and Disagreed

This wasn't a bug, exactly. It was the moment I realised the most expensive part of the architecture was also the most important.
The plan called for three supervisors from three different providers — Claude, Gemini, and GPT — each scoring every section independently and never seeing each other's reviews. Like blind peer review in academia. I'd designed it because one model reviewing its own work has blind spots, and I assumed three would catch more than one.
The shape on paper looked like this:
Every section flows through the same panel. Each supervisor scores it across four dimensions — plan adherence, quality, accuracy, flow — and a configurable voting strategy (average, majority, unanimous) decides whether the section ships or goes back for revision. The voting system never tells the supervisors what the others said.
What I didn't expect was how they would disagree.
Here's a real example from a run. Three supervisors reviewing a section called "Tears and Exits" — about World Cup elimination grief, of all things:
| Supervisor | Score | Verdict | What they caught |
|---|---|---|---|
| GPT | 8.0 | approve | Nothing flagged. "It's fine." |
| Gemini | 7.75 | revise | Caught a structural redundancy — the section recapped upsets already covered earlier in the article |
| Claude | 7.5 | revise | Caught the same redundancy, and flagged that the section needed concrete human imagery and a stronger emotional close |
GPT let it through. Gemini caught the structural problem. Claude caught the same structural problem and gave the most actionable feedback of the three:
"Remove the parenthetical recap of previously covered upsets. Anchor the section in one or two specific, named human images of elimination grief. Strengthen the closing connection between the reader's private losses and the shared public grief — this is the section's most powerful idea and it deserves more than one sentence."
Read that note again. That's not generic AI feedback. That's the kind of thing a thoughtful human editor would write — and it came from a model that had never seen the other two supervisors' opinions.
This is the moment the multi-supervisor design stopped being a nice idea and started being the point of the architecture. If I'd used GPT alone, that section would have shipped as-is. If I'd used Gemini alone, I'd have caught the redundancy but missed the imagery problem. The three together caught everything, and Claude's review told me exactly what to do about it.
Different models are wrong in different ways. That's not a flaw to be averaged out — it's the entire reason you'd build a panel in the first place. I'd designed it on instinct. The actual bug, in retrospect, was that I hadn't trusted the instinct enough — for a few hours during the build I'd considered cutting it down to two supervisors for cost reasons. Two-thirds of the panel would have meant two-thirds of the catches.
The Thing I Didn't Plan: Competitive Writing

This one wasn't in the 2,000-line plan at all. It came from looking at a single-writer pipeline and realising it didn't match how I personally use LLMs.
When I'm working on something important, I don't ask one model. I ask Claude and GPT and Gemini, and I compare. Sometimes I take the output from one and feed it into another for a second opinion. It's how I've used these tools for months. So when I caught myself building a system that would assign one writer per section, I stopped: Why am I building something I'd never actually do myself?
So I added a writing strategy called competitive. Multiple writers produce the same section in parallel from the same plan. A judge model — one with no skin in the game — picks the winner.
Here's what that looks like in practice. Same brief, same source material, same voice guide. Gemini 2.5 Pro versus GPT writing an intro about autonomous AI agents:
Gemini's version — analytical, builds toward the thesis:
"If you think the debate over AI is about smarter chatbots and better image generators, you're already looking in the rearview mirror. The public conversation remains fixated on generative tools — software that reacts to our prompts. But the more consequential shift is happening almost invisibly, as AI evolves from a passive respondent into an autonomous actor..."
GPT's version — direct, punchier:
"We're still arguing about AI as if the main event is text, images, and copilots. It isn't. The more consequential shift is quieter: software is moving from reactive systems that wait for instructions to goal-directed systems that can perceive, decide, and act across workflows with limited human intervention."
Same plan. Same research. Completely different creative choices. Gemini reaches for a metaphor and builds up gradually; GPT cuts to the thesis in two sentences. There's no objectively "better" version — there's only the better fit for the article's tone, which is exactly the judgment a human editor makes.
The shape is the same panel pattern as the supervisors, but used for a different purpose:
In that run, GPT won six of the seven sections. The one Gemini won was the only section where its longer, more narrative voice was the right call. It's not about the "best" model — it's about the right voice for the right moment. The judge picked accordingly.
The config is one line:
1writing: 2 strategy: "competitive" # "single" | "round_robin" | "competitive" 3 competitive: 4 writers: 5 - "section_writer" # Gemini 2.5 Pro 6 - "section_writer_2" # GPT 7 resolution: "judge" # or "merge" to combine the best parts
It doubles the writing cost. The total is still well under a dollar.
The Pipeline, Running
Here are real terminal captures from a live job. Six stages, one article, from the first search query to the final image summary.
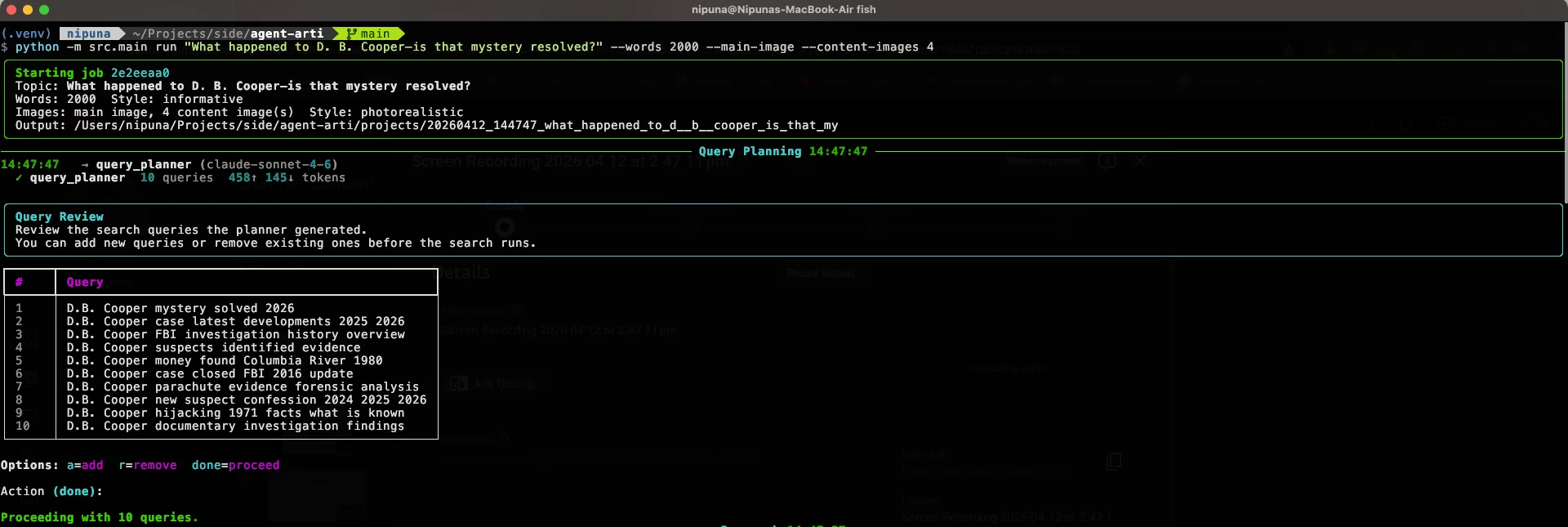
Research — query planning and Tavily search results
Research to publish, start to finish. The full run — six sections, three supervisors, competitive writing on, image generation — finishes in under two minutes.
What a Full Run Actually Costs
For the curious: a typical run of the full pipeline — 1,200-word article, six sections, three supervisors, competitive writing on, full research synthesis from three models — comes in around $0.60. A human freelance writer would charge $200–$500 for similar quality, although a human writer would also bring something the pipeline can't: actual taste.
That's the line I keep coming back to. The pipeline is good enough that I'd genuinely read its output. It is not good enough that I'd remove a human from the loop entirely. The two human gates — query review and angle selection — are still doing the most important work in the entire system, because they're the points where taste matters most.
The Lesson I Didn't See Coming
If Part 1 was about the value of brainstorming before coding, Part 2 has a quieter argument: the plan only gets you to the starting line.
Three of the most important features in this system — sequential rate-limit handling, fallback writers, competitive writing — weren't in the 2,000-line document. They came from running the thing and watching it fail in ways the plan couldn't anticipate.
That's not a failure of planning. The plan was right to exist. It saved me weeks. But the plan and the implementation do different jobs: the plan establishes the shape of the system, and the implementation tells you which parts of the shape are wrong.
The pipeline I'm running today is recognisably the one I designed at my parents' desk in Sri Lanka. It's also been quietly remodelled in three places by reality, which had opinions the architecture document didn't include.
If you want to build a multi-agent system, this is the part of the work nobody talks about — the patient back-and-forth between "what I designed" and "what the providers will actually let me do." Plan first. But leave room to be wrong.
The articles this pipeline produces are published at blueandyeliwrite.com.